Computational Literary Analysis
Description of the problem
One of the brilliant ideas that Kurt Vonnegut came up with was that one can track the plot of a literary work using graphical methods. He did that intuitively. Today’s question is “Can we track the plot changes in a text using computational or algorithmic methods?”
Overlaps between units of texts
The basic idea is to split a text into fundamental units (whether this is a sentence, or a paragraph depends on the document) and then convert each unit into a hash table where the keys are stemmed words within the unit, and the values are the number of times these (stemmed) words appear in each unit.
My hypothesis is (and I will test that in this experiment below) that the amount of overlap (the number of common words) between two consecutive units tells us how the plot is advancing.
I will take the fundamental unit as a sentence below.
A digression
For those who are not aware, there is a very lively debate on the number of spaces one should put after a full stop. Let me weigh in: in order to algorithmically process a text cheaply, I would need at least two spaces after a full stop, or any other symbol indicating the end of a sentence. Otherwise, one really needs appeal to computation intensive statistical or state-of-the-art NLP tools to parse the text to find out individual sentences. Why you ask? Try to split the following paragraph into sentences
Mr. Smith is from the U.S. but kept a house in the U.K. where he earned his Ph.D. in the 90’s while Mrs. Smith had successfully founded a company called “M.K. Robotics” which she later sold to IBM.
Implementation
First, some utility functions I am going to need later.
(defmacro ->> (x &rest forms)
(dolist (f forms x)
(if (listp f)
(setf x (append f (list x)))
(setf x (list f x)))))
->>I wrote about this in an earlier post. This is my CL implementation of the “thread last” macro in clojure. It is not a necessary feature, but IMHO it actually makes the code easier to read.
Here is another feature I am going to need from clojure.
(defun merge-with (fn &rest xs)
(let (res)
(dolist (x (reduce #'append xs) res)
(let ((val (cdr (assoc (car x) res :test #'equal))))
(if (null val)
(push x res)
(rplacd (assoc (car x) res :test #'equal)
(funcall fn val (cdr x) )))))))
MERGE-WITHI also wrote about it earlier. This function takes several association lists and combines them carefully: it uses the function passed to it to combine values associated with the keys that appear more than once.
Next up: a function that loads the text in its entirety as a single string. Not very efficient, but it will do.
(defun slurp (filename)
(with-open-file (in filename :direction :input)
(do* ((line (read-line in nil) (read-line in nil))
(res line (concatenate 'string res " " line)))
((null line) res))))
SLURPNext up: a function that cleans up a word:
(defun clean (str)
(->> str
string-downcase
(remove-if
(lambda (x)
(member x (coerce "0123456789`#!@$%^&*[]_+-=(){};'\:.\"|,/<>?" 'list))))
stem:stem))
CLEANThe function takes a string, converts the characters appearing into lower case characters, removes all extraneous characters and stems the result. I am using the common lisp implementation of the Porter Stemmer. If you are using quicklisp the library is called stem.
(require :stem)
NILNext up: a function that converts a unit of text into a hash table.
(defun bag-of-words (unit)
(->> unit
(split "\s+")
(mapcar (lambda (x) (cons (clean x) 1)))
(merge-with #'+)))
BAG-OF-WORDSNow, here is my measure of overlap:
(defun dot (a b)
(labels ((loc (x) (or (cdr x) 0.0d0))
(len (x) (reduce #'+ x :key #'cdr :initial-value 0)))
(let ((keys (mapcar #'car (append a b)))
(res 0.0d0))
(dolist (x keys (/ res (min (len a) (len b))))
(incf res (* (loc (assoc x a :test #'equal))
(loc (assoc x b :test #'equal))))))))
DOTThis function is a variation on the dot product of two vectors.
Finally, our main function.
(let* ((res (->> (nth 1 *posix-argv*)
(split "\.\s+")
(mapcar #'bag-of-words)
(remove-if #'null)))
(calculated (mapcar (lambda (x y) (cons x (dot x y)))
res (cdr res))
(i 1))
(dolist (u calculated)
(format t "~d ~4,3f~%" i (cdr u))
(incf i)))I ran this providing the name of the text file to be processed as an
argument. The term (nth 1 *posix-argv*) is exactly for
that. Be warned: this works for SBCL.
You should check the manual for your own local lisp implementation on
how to process the command line arguments.
Experiments
I ran my code with various texts. After I ran the code, I used R to plot the graph. I also did some smoothing using a running average with a window of size 5.
X <- read.csv("my-output",header=FALSE,sep=" ")
plot(filter(X[,2],rep(1,5)/5,sides=1))I chose two texts that I liked which are relatively short:
- Kennedy’s first inauguration speech from 1961, and
- Martin Luther King’s “I have a dream” speech from 1963.
Kennedy’s Inaugural Address (1961)
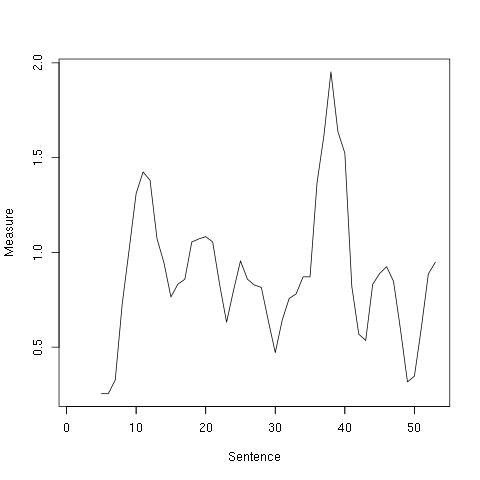
There are two peaks: the first at 12th sentence where Kennedy pledges “we shall pay any price, bear any burden, meet any hardship” to defend liberty, and around 38th where he iterates that the US will come to the aid of the “oppressed”. Apparently, he had to pause there because of the applause. I would say “expected” because he ramped up his rhetoric and his delivery right around that point.
Martin Luther King’s “I have a dream” speech (1963)
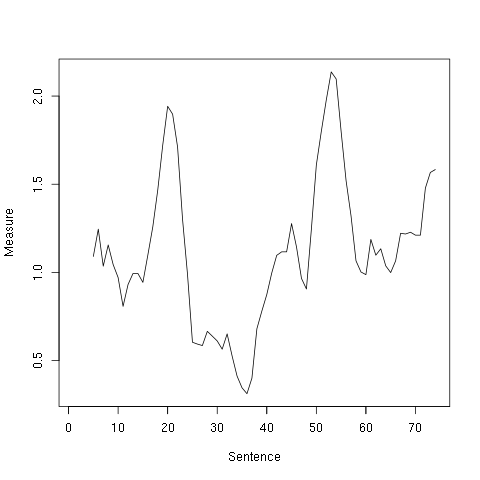
Let us look at places measure spikes:
- 18th to 22nd sentences: The rhetoric of MLK drives on the injustice on African Americans, and explains that “they came to cash a check.”
- 50th to 58th sentences: These are the “I have a dream” sentences.
- 68th sentence and onward: “Let the freedom ring” sequence.