Hamming Derivative of Hashing Functions
Description of the Problem
If \((X,d)\) is a metric space and if \(f\colon X\to X\) is a self map there is a quantity of interest: I’d like to see the distribution of the numbers defined for every \(x\neq y\)
\[\frac{d(f(x),f(y))}{d(x,y)}\]
In today’s note, the metric space is the space of bitstrings of a fixed length with the Hamming distance as metric and \(f\colon X\to X\) is going to be MD5 hash digest and SHA1 hash digest functions.
Implementation
I am going to need ironclad which is a native common lisp hashing and crypto library.
(require :ironclad)
NILwhich has the MD5 and SHA1 hashing functions:
(let ((hasher (ironclad:make-digest :md5)))
(defun md5-digest (x)
(coerce (ironclad:digest-sequence hasher x) 'list)))
MD5-DIGEST
(let ((hasher (ironclad:make-digest :sha1)))
(defun sha1-digest (x)
(coerce (ironclad:digest-sequence hasher x) 'list)))
SHA1-DIGESTThe function md5-digest will return the digest as a list
of 16 bytes (unsigned 8-bit integers). The space of bit strings of
length 128 is large. So, I will use a Monte-Carlo method which requires
for us to generate random byte strings of length 16:
(defun random-vector (m)
(coerce
(loop repeat m collect (random 256))
'(vector (unsigned-byte 8))))
RANDOM-VECTORNow the function that calculates the ratio we are interested in
is
(defun hamming-distance (x y)
(labels ((calc (x y &optional (acc 0))
(cond
((< x y) (calc y x 0))
((zerop x) acc)
(t (calc (ash x -1)
(ash y -1)
(if (equal (oddp x) (oddp y))
acc
(1+ acc)))))))
(reduce #'+ (map 'list (lambda (i j) (calc i j)) x y))))
HAMMING-DISTANCENow, let me test this on a sample of size 12000 on MD5:
(with-open-file (out "hamming-data.csv" :direction :output
:if-exists :supersede
:if-does-not-exist :create)
(loop repeat 12000 do
(let ((x (random-vector 16))
(y (random-vector 16)))
(format out "~4,2f~%" (/ (hamming-distance (md5-digest x) (md5-digest y))
(hamming-distance x y)
1.0)))))
NILHere is a histogram of the data:
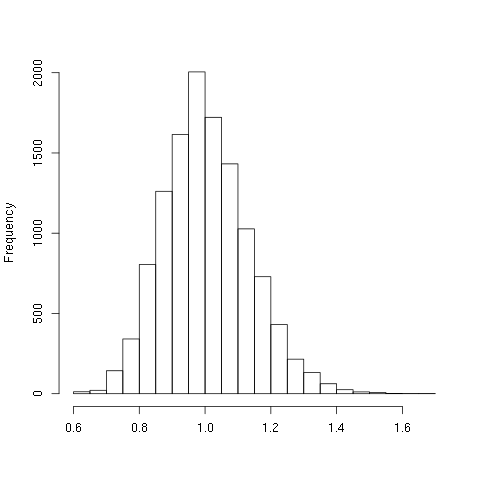
Now, let me test this on SHA1. This time, the random vectors are of length 20 because SHA1 digest produces 20 bytes:
(with-open-file (out "hamming-data2.csv" :direction :output
:if-exists :supersede
:if-does-not-exist :create)
(loop repeat 12000 do
(let ((x (random-vector 20))
(y (random-vector 20)))
(format out "~4,2f~%" (/ (hamming-distance (sha1-digest x) (sha1-digest y))
(hamming-distance x y)
1.0)))))
NILHere is a histogram of the data I produced above:
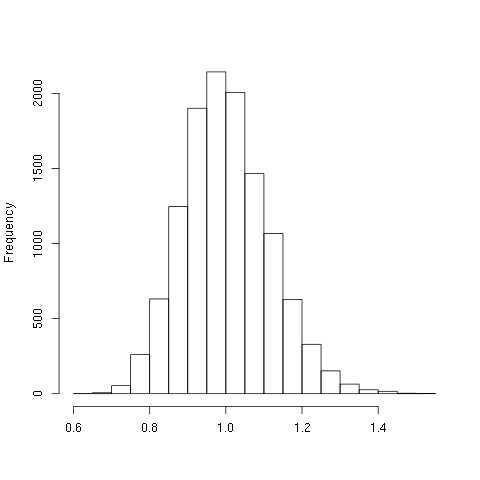
I am going to use Kolmogorov-Smirnov
test to see if these distributions are similar. The result below
indicates that even though the statistic is small, the p-value tells us
that the distributions we see here are actually very different.
Two-sample Kolmogorov-Smirnov test
data: X and Y
D = 0.0365, p-value = 2.28e-07
alternative hypothesis: two-sided